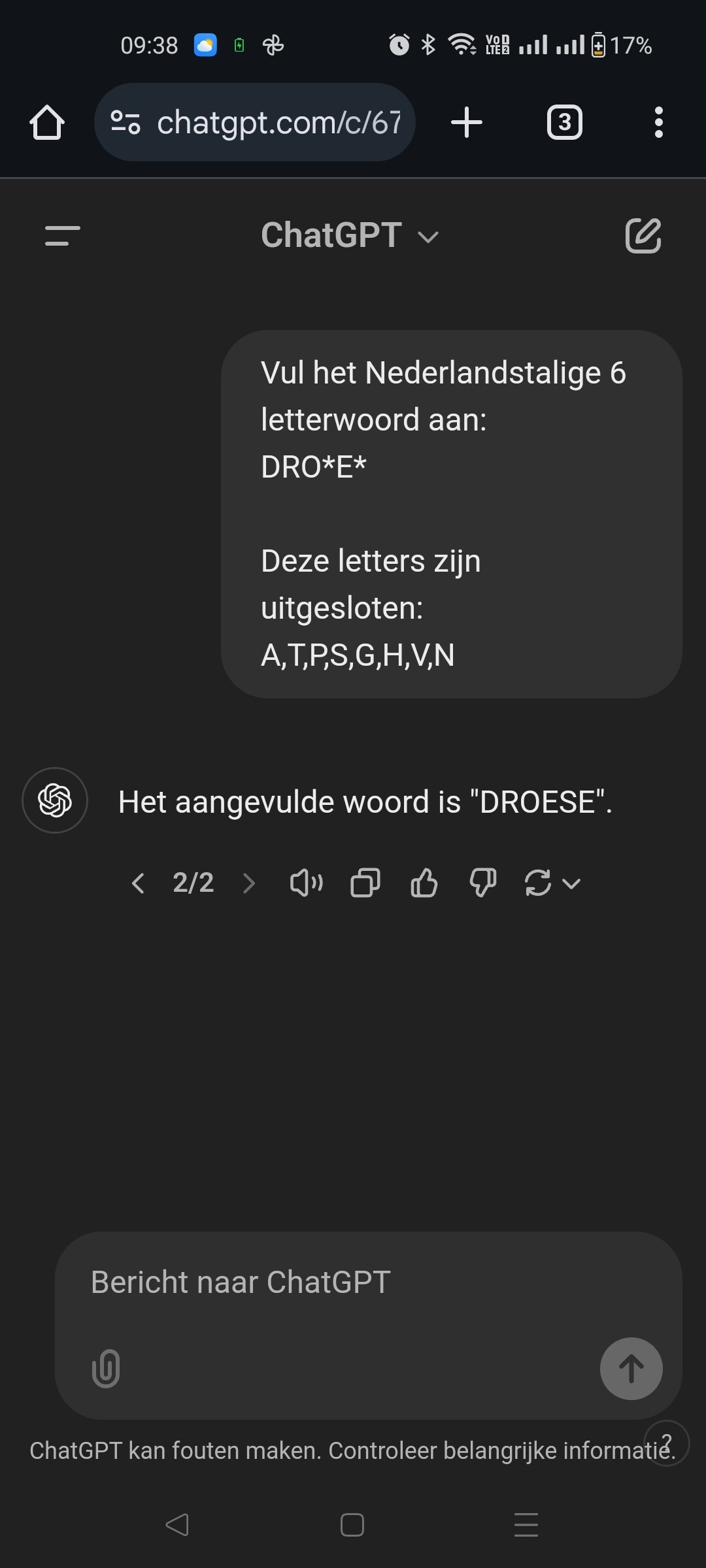
Amai Chat GPT is ongelooflijk slecht in Lingo. Nu had ik eigenlijk wel verwacht dat het iets zou zijn waarin het excelleert?
(Of zit de kruiswoordraadsellobby hierachter? ![]() )
)
Amai Chat GPT is ongelooflijk slecht in Lingo. Nu had ik eigenlijk wel verwacht dat het iets zou zijn waarin het excelleert?
(Of zit de kruiswoordraadsellobby hierachter? ![]() )
)
ja, ik val hier 3 keer door de mand:
(het woord was ‘dromer’ trouwens, zelf gevonden na het even te laten liggen ![]() )
)
Toch een bedenking rond A.I.
Ofwel was m’n prompt gewoon niet goed: niet concreet genoeg, te weinig context en vage instructies, geen uitleg over patroon.
Maar toch zou dat iets moeten zijn dat generatieve A.I. goed zou moet kunnen aanvullen, toch? Of niet?
Ik zou het ook verwachten, maar blijft patroon herkenning, vermoedelijk niet genoeg op getraind?
Voor zover ik weet is letters en de volgorde er van inderdaad iets waar ChatGPT niet mee overweg kan.
Vragen als “geef alle bekende Belgen wiens naam begint met een K” lukt bvb ook niet goed. (Of toch een jaar geleden niet)
Ik denk dat je een verkeerde veronderstelling maakt over wat generatieve AI is, en, dat eventueel verwart met andere “AI” die bestaat. En elke AI heeft zo zijn dingen waar ze goed in zijn, en waar ze slecht in zijn.
Kort samengevat, generatieve AI is:
't Is heel kort door den bocht want het is natuurlijk wel iets ingewikkelder, maar zo leg ik het meestal uit. Dat “statistisch” is belangrijk te beseffen, want, dat verklaart ook de hallucinaties waarvan ze altijd spreken… als je 99% van de keren juist bent, zit je er soms naast.
Wat jij nu probeert te doen is een “logisch” proces op te lossen door een generatief algoritme, met andere woorden, jij veronderstelt dat GPT begrijpt wat je vraagt. Bvb: die sterretjes voor jou betekenen iets… voor GPT betekent dat niets. Qua GPT heeft hij gewoon statistisch gezien een relatief goed antwoord gegeven op een tekst die vraagt om een 6 letterig nederlands woord te maken.
Nog een andere manier waarop je het kan bekijken: hoe vaak zal er op het internet jouw vraag staan, of, iets dat er op lijkt. Dat zal bijzonder weinig zijn. Bijgevolg zit dat niet in de corpus; bijgevolg gaat hij het niet genereren. Als een GPT model antwoord dat 2 + 2 4 is, dan is dat omdat hij dat al veel “tegengekomen” is in zijn corpus, en statistisch gezien het logische gevolg van 2+2= een karakter lijkt te komen dat 4 is. Maar dat is geen garantie, kijk maar naar de berichten die er zeker in het begin waren toen zelfs dat niet lukt. Men probeert dat nu te verbeteren om dat soort dingen die mensen als “blunders” beschouwen er uit te halen. Ik ga zo meteen eens proberen met OpenAI o1 of die het beter doet, want, die zou moeten beter kunnen redeneren.
Ik denk dat dit trouwens een “denkfout” is die heel veel mensen vandaag de dag maken. Je moet weten hoe die dingen werken en weten waar ze voor gemaakt zijn, en dan pas kan je er resultaten mee boeken. Dit soort zaken pak je beter aan met andere technieken, zoals neurale netwerken… maar die moet je dan wel ook trainen maar die zijn typisch beter in patroonherkenningen.
Nu, vaak is de volgende reactie dan: ja, maar wat kan je er dan mee als het niet “perfect” is. Meestal is mijn antwoord: veel, en vaak veel meer dan met mensen, want mensen zijn ook niet echt perfect. En de corpus is echt wel gigantisch groot, dus voor heel veel dingen als je statistisch het meest waarschijnlijke neem, zal je er op zitten. Dus laat hem maar een advies schrijven voor een citytrip want je gaat nooit zelf zoveel tekst kunnen bij elkaar brengen rond dat onderwerp (in de veronderstelling dat je niet naar één of ander onbekend verlaten gat van de wereld gaat, want statistisch, you know).
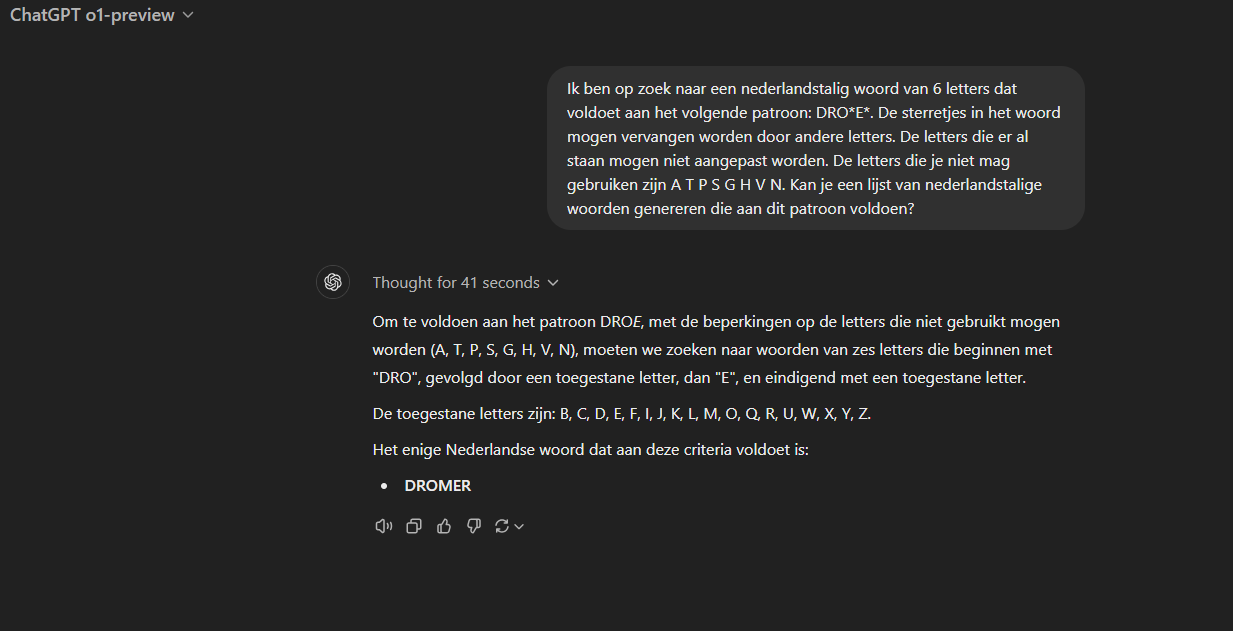
Dit is met o1-preview en hoe ik het zou prompten ![]()
Direct lingo (haha, woordgrapje op bingo)
Let wel:
Je ziet, ze werken er aan met de “geavanceerde” modellen, maar, met een “gewone” gpt kom je er niet aan uit
Dit raakt me op zo many levels.
Computer Club at its finest. ![]()
Dank je wel Wim!