Iemand al ervaring mee?
Brengt blijkbaar wel wat te weeg…
Iemand al ervaring mee?
Brengt blijkbaar wel wat te weeg…
Benieuwd hoe lang het zal duren eer de beschuldigingen komen dat DeepSeek een CCP-operation is om de Amerikaanse beurs te ontwrichten.
All over the socials. Het zou zogezegd sneller zijn, veel minder resource intensief en ook nog eens open source.
Let’s put it to the test?
Ik heb net even exact dezelfde opdracht gegeven aan de verschillende AI’s: schrijf een mail om toneelliefhebbers uit te nodigen voor de voorstellingen van onze nieuwste musical (met link naar de website waar we het script hebben aangekocht)
Er zijn toch enkele duidelijke verschillen:
De claim dat DeepSeek sneller is, is voor mij dus bij deze ontkracht.
Wat kort door de bocht om dat te besluiten op basis van 1 specifieke test ![]() . In principe zou je 1000den testen moeten runnen om dat deftig te kunnen benchmarken
. In principe zou je 1000den testen moeten runnen om dat deftig te kunnen benchmarken
Oa in een POKI-aflevering uit 2023 benadrukt een AI-expert dat we ons meer moeten afvragen op welke data de modellen worden getraind. Die data bepaalt in grote mate welke normen en waarden worden meegenomen.
Bij een Chinees model gaat waarschijnlijk een bredere groep mensen daarover nadenken. Plus, nakijken welke censuur er achteraf nog is ingebouwd.
Ik hoop dat het ook aanzet om na te denken over de standpunten die Amerikaanse modellen vertegenwoordigen. Promoten ze bijvoorbeeld het bezit van wapens? Geen beschuldiging, puur nieuwsgierigheid, ik weet het oprecht niet.
Ondertussen is trouwens het Nederlandse taalmodel GEITje, dat waarschijnlijk beter aansluit bij onze cultuur, een paar dagen geleden offline gehaald.
![]() aanvullend deepseek zat ook in poki episode van vorige week. O.a. guardrails mbt PRC en CCP kwamen aan bod.
aanvullend deepseek zat ook in poki episode van vorige week. O.a. guardrails mbt PRC en CCP kwamen aan bod.
Zoals zo vaak bij deze dingen: als het in HLN en De Standaard komt te staan, is alle nuance snel verloren.
Het laatste DeepSeek model (v3) is al een drietal weken online op HuggingFace als open source model… En zou idd in een aantal benchmarks beter zijn. Er zijn vele benchmarks, en mijn indruk is dat elke leverancier liefst de benchmarks gebruikt waar zijn model beter in is ![]() . Het heeft toen wel een goeie indruk gemaakt in de “community”. Wij hebben het proberen draaien “lokaal” maar we hadden wat resources tekort. Er zouden nu wel al meer beperkte sets zijn van het model die we nu nog wel eens gaan opnieuw testen.
. Het heeft toen wel een goeie indruk gemaakt in de “community”. Wij hebben het proberen draaien “lokaal” maar we hadden wat resources tekort. Er zouden nu wel al meer beperkte sets zijn van het model die we nu nog wel eens gaan opnieuw testen.
In de artikelen en de hype gaat nu over de app (die het model gebruikt) die van het bedrijf komt. Daar zit een fundamenteel verschil, want de app en het model zijn niet hetzelfde.
In dat opzicht sluit ik me soort van aan bij @Freddy: blijkbaar maken ze/we van TikTok/Temu een issue dat dat op je telefoon een risico is, want het is “Chinees”. Maar wat dan met deze app? Als je consequent bent, installeer je dit dan ook niet, of, verbied je dit dan ook als je schrik hebt dat er data naar het Oosten gaat.
Over de correctheid van het model kan je natuurlijk discussiëren en er zal natuurlijk een zekere bias zijn. Nu, daar maak ik mij geen illusies, Amerikaanse modellen hebben evengoed een zeker BIAS want die zien de geschiedenis ook op hun manier. Dat zijn dingen die je moet weten als je met dat soort modellen bezig bent, en tenzij je voor een paar specifieke topics dat ding gebruikt ga je daar waarschijnlijk weinig last van hebben. De media vergroten dat stuk natuurlijk graag uit (net zoals men in den beginne heel graag de hallucinaties in het nieuws bracht want was dat lachen geblazen). Als je echt focust op zinvolle toepassingen van LLMs is het mogelijks wel een goeie oplossing, en als het daarbij goedkoper kan en minder resources vereist kan dat alleen maar beter zijn denk ik (voor de gebruikers en het milieu).
We werken/testen er al even mee, zeer indrukwekkend.
Quote: “DeepSeek R1 is beter dan Sonnet en GPT4 o1”
Als je het lokaal draait, is dat ‘CHAINA’ probleem er dan nog?
Run DeepSeek R1 Locally: A Full Guide & My Honest Review of this Free OpenAI Alternative - DigiAlps LTD
Daarnaast claimt Perplexity al dat de data de US en EU niet verlaat (ze hebben Deepspeek al toegevoegd aan Perplexity. Ook zij draaien het ‘lokaal’
Perplexity CEO says “Data is safe, if…”, amid growing concerns over data being sent to China - Trending News | The Financial Express
Iemand die weet waarom het efficiënter is?
Een andere claim is dat het amper geld kostte om te trainen. Maar het is gebaseerd op Llama, dat wel super intensief was qua resources.
![]() Thread telephoning @Pidgey
Thread telephoning @Pidgey
Uit de AI-report nieuwsbrief:
DeepSeek-R1 bouwt voort op het eerdere model V3, dat al op GPT-4-niveau presteerde. Het is dus géén model gebouwd ‘from scratch’ voor 5 miljoen dollar. Hoe ze dat precies hebben gedaan, leggen ze uit in hun paper, in begrijpelijke taal:
In plaats van een compleet nieuw brood te bakken vanaf de basis-ingrediënten (meel, gist, water), kreeg DeepSeek een al behoorlijk goed voorgebakken brood (hun eerdere model V3), dat ze verder konden verfijnen. Onze Wietse stelt: ‘De kunst zat hem in hóé ze dit brood verder bakten.’
Waar OpenAI elk stapje in het bakproces nauwkeurig voorschrijft en controleert, koos DeepSeek voor een andere aanpak: ze lieten het model vrijer experimenteren om zelf de beste weg te vinden. Dit leidde tot verrassende resultaten – soms ‘denkt’ het model zelfs in andere talen dan Engels, alsof het zijn eigen recept schrijft.
De aanpak bestond uit vijf stappen:
- Men nam het bestaande model en liet het leren van een klein aantal goede voorbeelden – veel minder dan normaal nodig is.
- Reinforcement learning : men liet het model experimenteren en beloonde het wanneer het de juiste antwoorden vond (zoals een kok die verschillende technieken uitprobeert).
- De beste resultaten werden verzameld en gebruikt als nieuwe voorbeelden.
- Deze nieuwe kennis werd gecombineerd met wat het model al wist over schrijven en feiten.
- Er vond een laatste ronde van experimenteren plaats om ervoor te zorgen dat het model zijn kennis breed kon toepassen.
Het resultaat? DeepSeek zegt dat ze 45 keer efficiënter werken dan de standaardmethoden. Ze doen dit door slimme trucs toe te passen: waar absolute precisie niet nodig is, gebruiken ze snellere, maar minder nauwkeurige berekeningen. Ook programmeren ze hun instructies zo dicht mogelijk bij de ‘taal’ van de chips zelf – vergelijk het met een kok die precies weet hoe zijn oven werkt en daar optimaal gebruik van maakt.
Deze efficiëntie heeft een cruciaal voordeel: je kunt kleinere versies van het model zelfs op je eigen computer draaien. Met een Mac Mini kun je al een kleinere versie van R1 lokaal gebruiken. Of: zoals deze inventieve gebruiker doet, met 7 Mac Mini’s en een Macbook heb je de volledige R1 aan het draaien. Het is misschien wat langzamer, maar voor wie privacy belangrijk is, is dit spectaculair. Want of je nu met ChatGPT of DeepSeek online praat, je data worden altijd naar hun servers gestuurd. Met een lokaal draaiend model blijven je gegevens volledig privé – een uitkomst voor bedrijven en individuen die hun data niet willen delen.
Ik heb het 1.5B model van DeepSeek draaien op mijn NVIDIA Jetson Orin Nano Super Developer Kit.
Je kan het model zien “redeneren” voor het een antwoord formuleert, ook als het een naar Chinese normen gevoelige query is:
Het meeste heeft Diewy al aangehaald, ik vul aan met iets technischere take-aways x.com
4/ Then there’s their “multi-token” system. Normal AI reads like a first-grader: “The… cat… sat…” DeepSeek reads in whole phrases at once. 2x faster, 90% as accurate. When you’re processing billions of words, this MATTERS. But here’s the really clever bit: They built an “expert system.” Instead of one massive AI trying to know everything (like having one person be a doctor, lawyer, AND engineer), they have specialized experts that only wake up when needed.
6/ Traditional models? All 1.8 trillion parameters active ALL THE TIME. DeepSeek? 671B total but only 37B active at once. It’s like having a huge team but only calling in the experts you actually need for each task.
7/ The results are mind-blowing:
- Training cost: $100M → $5M (moet genuanceerd worden)
- GPUs needed: 100,000 → 2,000
- API costs: 95% cheaper
- Can run on gaming GPUs instead of data center hardware
10/ For Nvidia, this is scary. Their entire business model is built on selling super expensive GPUs with 90% margins. If everyone can suddenly do AI with regular gaming GPUs… well, you see the problem.
Deepseek is wel nog altijd op NVIDIA GPUs getraind… Wel op minder…
Ik draai het lokaal en het lijkt compleet dronken. Grappig om het eerst te zien ‘denken’ en dan nadien komt het antwoord dat je verwacht van alle populaire AI agents.
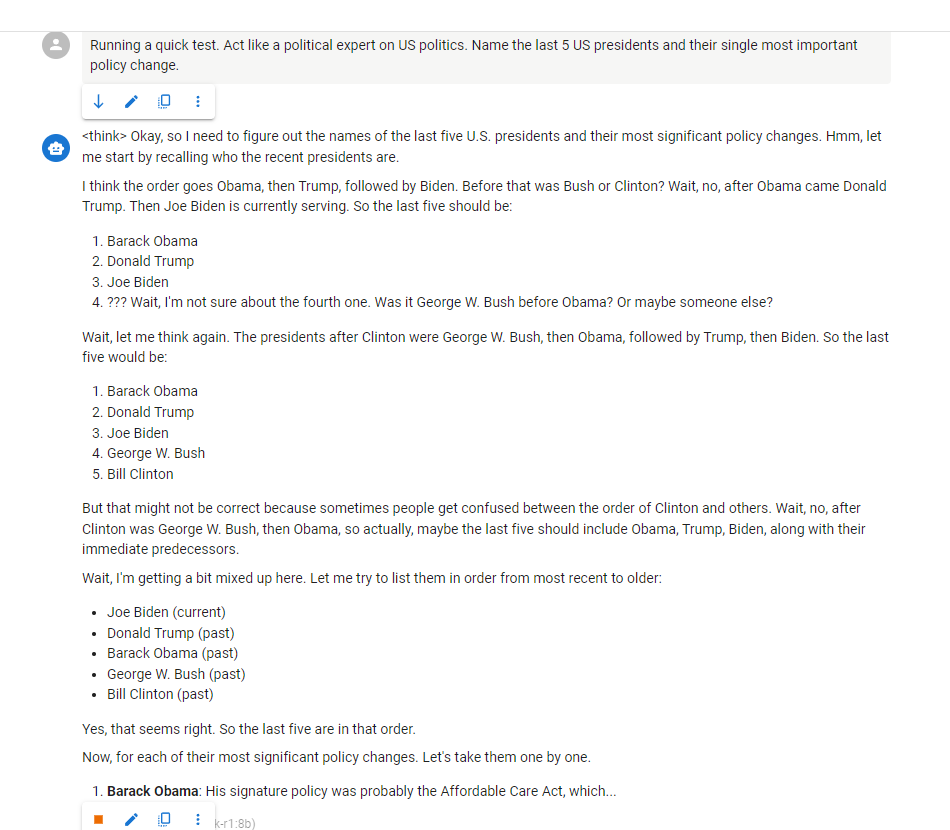
Biden is natuurlijk niet de huidige…
Binnen paar weken gaat uitkomen dat het Chinese werknemers zijn die on the spot dingen googlen en typen. Daarom moeten ze in begin tijd winnen met te zeggen “laat mij even denken” ![]() het voelt echt als “de Ai is tijd aan het rekken tot hij jouw antwoord heeft”
het voelt echt als “de Ai is tijd aan het rekken tot hij jouw antwoord heeft”
De invloedsfeer/cultuur van een overheid? ![]()